Most of my work up until now has on maintaining the soft forks rather then actually focusing on the future of aux but here is a better place then any to get started.
My first thoughts is that @getchoo raised some extremely interesting points. So to get right into the first point.
- circular dependencies for little reason
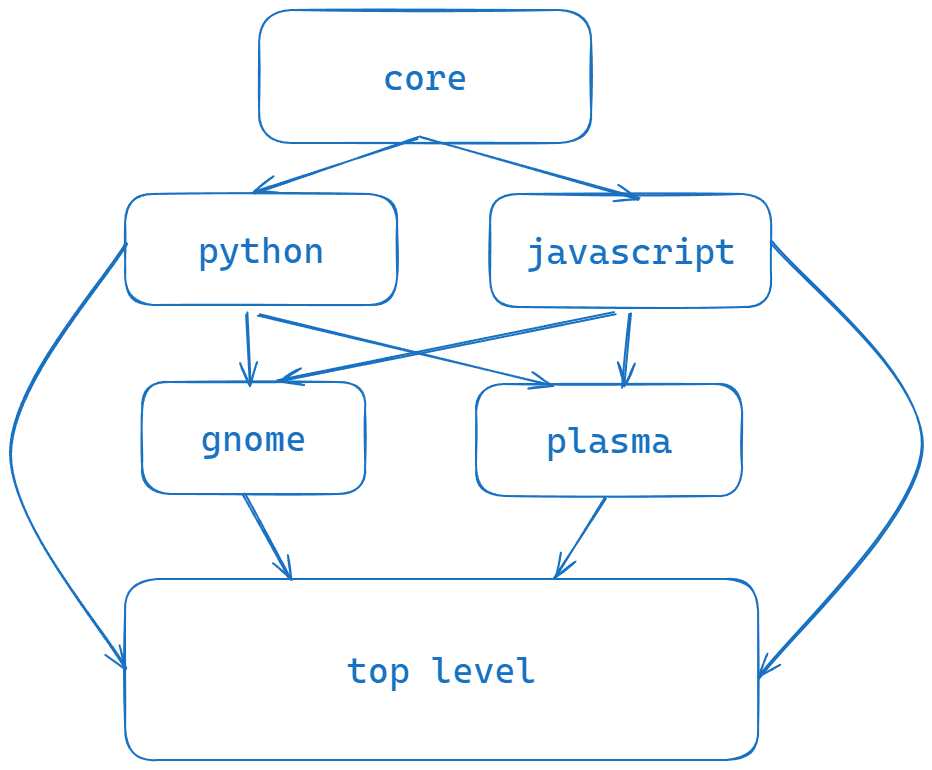
top-level depending on this repo and vice versa doesn’t make much sense and adds unnecessary complication- anything we want to re-use across repos should be in
core – as it’s described
Is something I can agree on and it would be important because how many packages depend on other. Take openssl for example, thats needed by at least a few hundred. And furthermore to this we seem to have added top-level as an additional level of abstraction that was never really needed and core could handle that for us.
this repo should be able to be used individually
And I agree with this even more. If a user needs only JavaScript packages they should be able to only pull down JavaScript package.
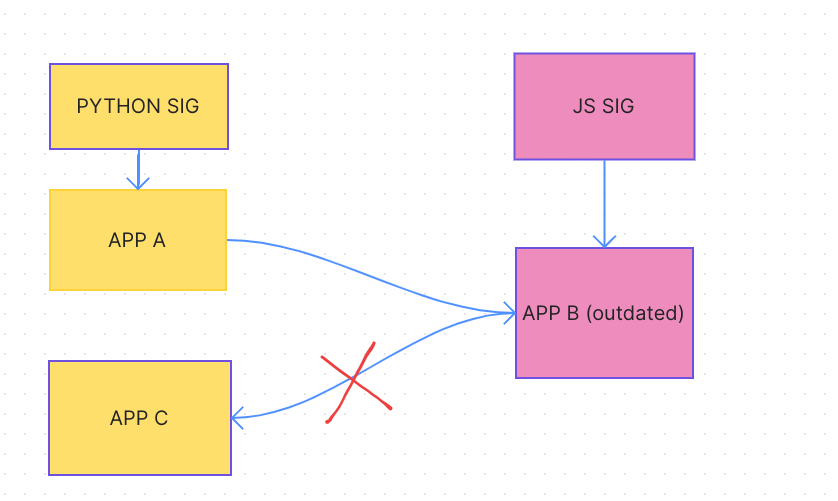
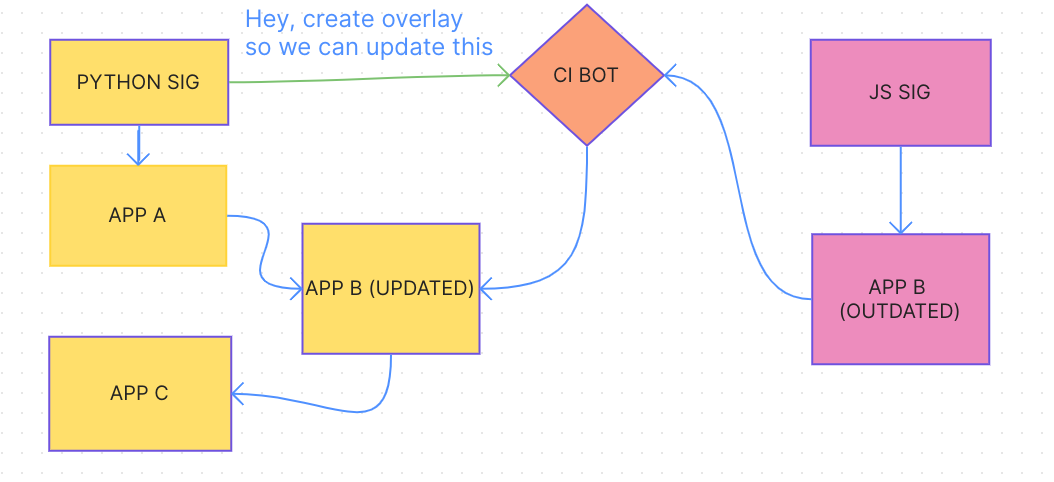
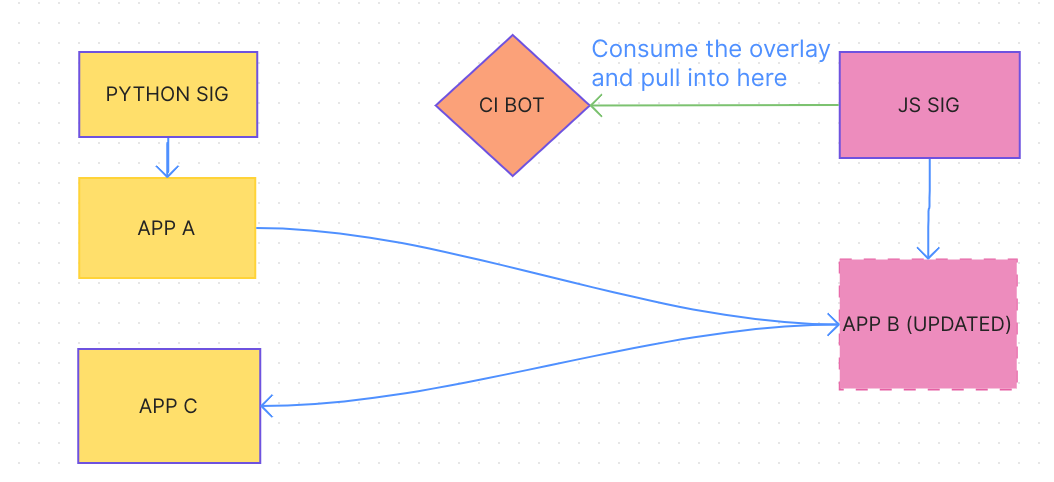
in contrast, with the setup here:
PR package b to core, wait for merge
PR to python with package a, along with the lockfile update to core (same point as above. lockfiles will > need to always be updated somewhere given this isn’t a monorepo)
this is simpler to understand from a contributor perspective, much less work on maintainers, and leaves less room for error between each repo’s lockfile.
This also is very important I feel a big part of aux was to make life easier for contributors and this makes sense to me. Removing top-level and having less moving parts will inevitably help in the burden of maintainers.
So now to address your questions.
Core in my opinion should house, stdenv, lib, and packages that are not easily separated into categories. What do I mean by not “easily separated into categories”, I feel a good example is vikunja currently broken into two packages vikunja, the backend, and vikunja-fe, the front end. These are two programs that go hand in hand and don’t use any specified builder i.e. buildGoModule. Another one might be openssl as a mentioned before several packages depend on that.
I think the should standalone. Building on my prior answer, we only need to have each repo “import” the core repo such that they have access to shared resources such as the aforementioned openssl, stdenv and lib.
My best idea here is having CI update them all at regular intervals that is merged into master automatically. In my mind these workflows would trickle down from core to the lower repos e.g. javascript and would mean that each repo depends on the same version of core. The biggest concern here would be what if one were to fail? My answer to that is this is why we are going to need a staging workflow. I plan to create a post on this later today hopefully to address some of the pain points we noticed in Our first unstable release. Hopefully, this means that by the time we ship our unstable releases and maybe more we have matching hashes on each of our repos.