Just food for thought, one nitpick I have with Nix is the focus on everything being within the monorepo first, and getting packages from the developer directly as a flake or something else second. I’m curious what people think about the flatpak model of separating backend libraries into runtime groups that are used by the developer to package an application. The main issue I see is along the lines of 1000 instances of nixpkgs. Any thoughts?
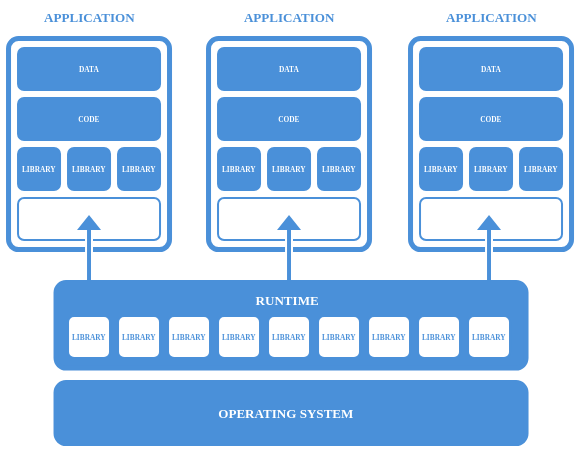
Basic concepts - Flatpak documentation
7 Likes
Was going to make this post myself, though my comments are more general, just going to leave my message below.
One of the good parts of forking is that we now have the optiunity to redefine ourselves. And one of the things I personally think nix was known for was having a bad time making your first contribution.
Part of this problem was the length of the maintainers.nix file which crashed vscode for me 2 times. And the size of the repo alone slows down the any editor even a basic vim install.
One of the good things we can do is breakup the current monorepo into subsections similar to how the linux kernel is managed.
4 Likes
Spliting things up might allow a quicker response to security vulnerabilities.
3 Likes
Directly in each repo yes, but also consider that now every dependant must make sure to update the dependency with a vuln rather than just everything being fixed all at once within the monorepo. Especially with what I mentioned of developer distributed software, there would still need to be a way to force update a dependency runtime. Perhaps using semantic versioning could work, but that then requires even more maintenance overhead.
3 Likes
I was thinking about this the other day. The problem we are trying to solve here is almost purely on the maintenance side, not on the consumer’s side. From a maintenance perspective, breaking apart different domains can help maintainers iterate quicker, but from a consumer side having to then manage multiple (likely inter-dependent) flake inputs is not ideal. So what if we cheated a bit?
Instead, we break nixpkgs out into multiple domains which can be effectively managed by individual groups:
- Core
- Rust
- Extras
- …
And then we have a single flake which links them all back into one package set. That way users only actually have to deal with, say, github:auxcomputer/packages. You get the same consumer semantics as nixpkgs, but the maintenance side can be distributed. This may also make releases or specific augments easier due to this gating!
16 Likes
Well I’m glad to see you guys have done all the work of writing my ideas out for me haha. Especially in the light of flakehub and a small team I agree distributed is necessary.
In the nix Discourse I have a few long posts about how we can integrate distributed and monorepo nicely, and basically go at our own pace.
(I dont mean to skip over your idea @jakehamilton, I’ll just have to respond on that another time since this post of mine is mostly copy paste for me)
The idea is simple, packages have one job; update themself as fast as possible on their own repo get their test suite passing using whatever dependencies they want. Ideally depending on a tagged monorepo release like 23.11. Not much to explain.
On the other hand, the monorepo has a much harder job, but still just one job; get an “all green” bundle of packages. Meaning, every package has its inputs overridden to use monorepo inputs instead of whatever pinned-input was used by the individual package repo. E.g. python (depending on nixpkg23-11.glibc) gets changed to python depending on self.glibc, and we want all the tests to keep passing.
Let’s say we start with an old but “all green” monorepo.
What do we do?
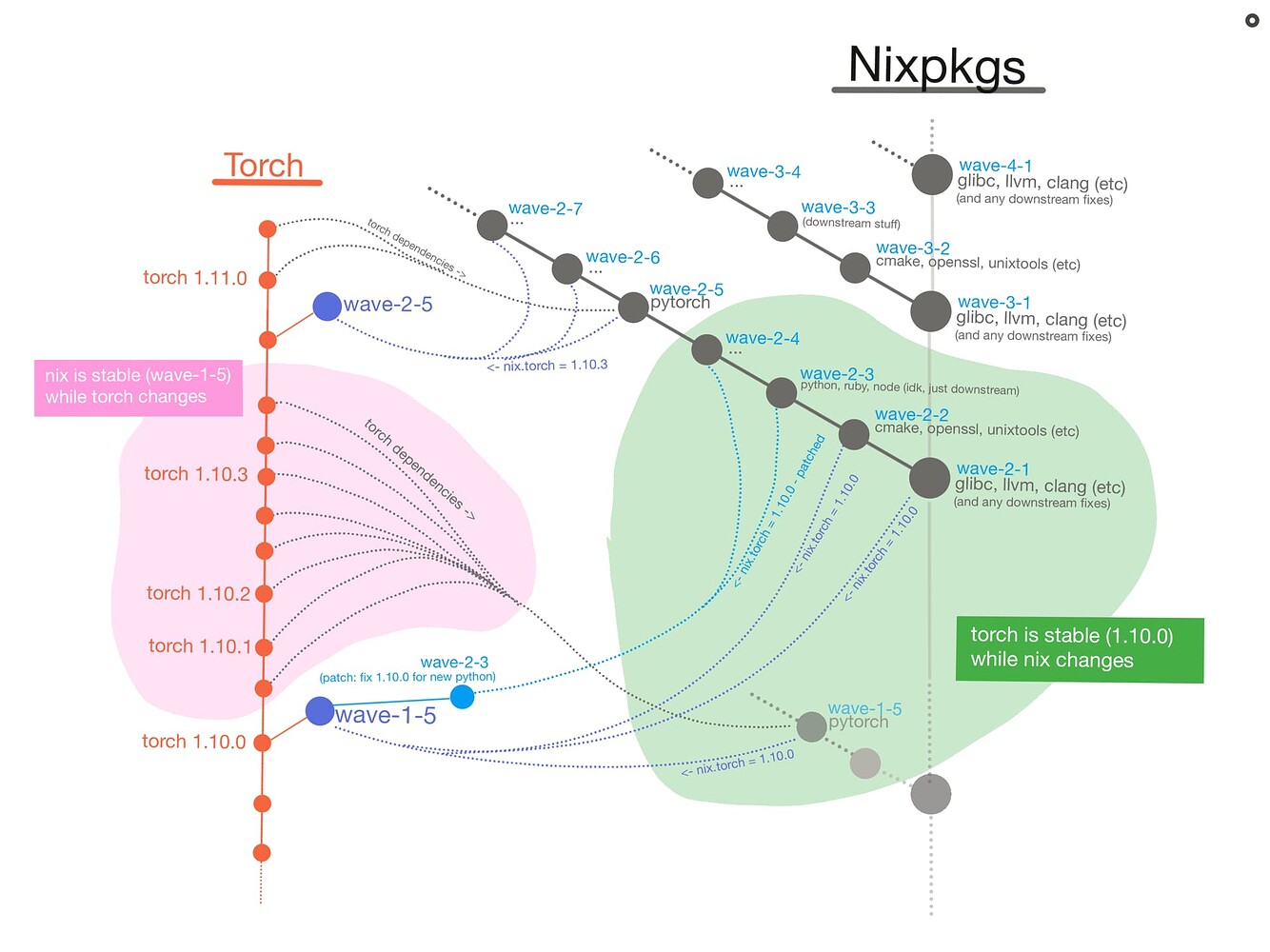
Let’s start, what I call, major waves. Every major and minor wave is its own git branch. So actually let’s start two major waves because we can do waves in parallel.
WIP-Wave1.1: we update the glibc of the monorepo to idk, glib latest-2
WIP-Wave2.1: we update the glibc of the monorepo to glibc latest -1
Well everything is broken now (probably). So we stay on WIP-Wave1.1 making whatever changes to downstream packages, like updating python to 3.11, to get them working with the new glibc. Whatever it takes to get tests passing, including marking some packages as broken. As soon as all the tests pass, we have reached an “all green” status. We can rename from WIP-Wave1.1 to just “Wave1.1”. At the same time we do the same thing on wave2.1.
The first minor wave is the most difficult because “test downstream” means “test EVERYTHING”. On the second minor wave WIP-Wave1.2, and WIP-Wave2.2, we update something “below” glibc, like llvm. That breaks everything again, we fix them all again and repeat. I say glibc and llvm because pretty much everything depends on them, they’re at the root. For example, numpy depends on python depends on llvm depends on glibc. The minor waves go in reverse order. Ex: the minor wave updates python, and fixes everything below python. The next minor wave tries to update numpy, and to fixes everything below numby.
The monorepo is never going to have the latest versions because it takes forever to test stuff. But that’s okay because if you want the latest version, just pull it down from the individual package flake on flakehub.
Using pytorch as an example package, and nixpkgs as the monorepo. This is what their commits (dots) might look like. Arrows means dependency.
My initial thoughs are; probably a lot of work to do this straight up, so maybe try just making any kind of monorepo first and eventually get to this system. Either that or we start with this system with a subset of packages (80/20 rule) to limit complexity and compute.
Also maybe @jakehamilton 's
grouping idea could be nicely combined with this approach.
2 Likes
Sorry, I’m kind of confused. So you’re saying from a top level tree, to update packages, and then propagate those updates, and every time we do to update the minor version counter (the y in x.yy), until we’re totally done. And then we keep doing that, incrementing the x counter. Is that not the same as how nix is, with each 6 month release?
AFAIK nixpkgs is much more sporadic. I don’t think its top down, they just update packages like glibc on a hand picked basis. Also this wouldn’t ever have a 6 month release. Waves just exist as soon as theyre done with tests.
Also while I think the idea is simple once its “in your head” explaining it is really hard and I haven’t found a great way to do it.
Let me know if this answers your question
Wave1.0
- glib0.1
- llvm0.1
- python0.1
- numpy 0.1
Wave1.1
- glib1.0 ← update to latest
- llvm0.1 (test and fix)
- python0.1 (test and fix, ex: maybe bump to python 0.2)
- numpy 0.1 (test and fix)
Wave1.2
- glibc1.0 (dont touch dont test)
- llvm1.0. ← update to latest
- python0.1 (test and fix)
- numpy 0.1 (test and fix)
Wave1.3
- glibc1.0 (dont touch dont test)
- llvm1.0 (dont touch dont test)
- python1.0 ← update to latest
- numpy 0.1 (test and fix if needed)
Wave1.4
- glibc1.0 (dont touch dont test)
- llvm1.0 (dont touch dont test)
- python1.0 (dont touch dont test)
- numpy 1.0 ← update to latest
Wave1.1 rebuilds everything and tests everything; extremely expensive. Wave1.4 just rebuilds numpy and tests; relatively cheap
Meanwhile:
- python 0.1, 0.2, 0.3, 0.4, 1.0, 1.1, 1.2, 1.3 have all been published on the python flakehub, using glibc0.3 as an input
Instead, we break nixpkgs out into multiple domains which can be effectively managed by individual groups:
This is a really interesting idea. Especially since nix already halfway does this. I’m going to have to think about this a lot and how to maybe formalize a “subtree” definition and give them a common interface that is still flexible enough to handle the absolutely massive differences that exist between package systems.
But, that aside I can absolutely say right now I fully support having “core” in a separate repo. If there was one thing I could change about nixpkgs it would be having core isolated from everything else.
3 Likes
Right, but the criteria for “don’t touch dont test” is that you need to make a dependency tree for the ENTIRE repo and create levels for each one and handle it like that. To me, this just seems like a worse version of hydra because, depending on how fast each wave subversion is handled, you have things near the top of the tree getting stale and outdated, and if you want to update that you just bumped up the major version by one and you have created a TON of work again. Also, with how complex nixpkgs is, the versioning on this would be insane, since you need a separator for each level to define what stage its in – 1.23.21.1.2.23.178.82…, which would get confusing fast. I think the split repo approach that lets faster iteration happen is a more appealing option.
I like the idea in theory, but I can’t imagine that we have the infrastructure for so many parallel lines of waves to process through and contributors to make sure it goes smoothly.
Also, say for the top level dependencies, when do you decide to update it? Say you have 5 packages in the top level and 1 is outdated. Do you do a new wave? Do you save it when 2 are outdated? 3? All? It seems arbitrary, and its made worse as you go down the tree and the scope of each level widens.
1 Like
Yep, for the tree, we’ve already got deps tree for the entire repo, theres a tool for it.
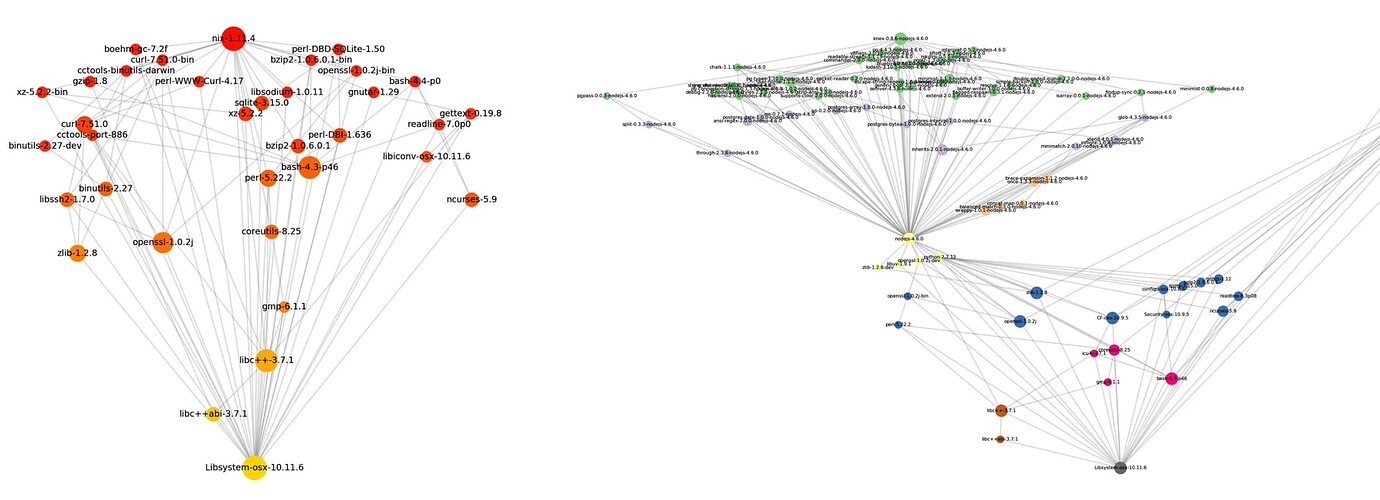
Your other criticism is valid, it would be a lot of cycles. But the top wouldnt get stale because each new major wave refreshes the top first. It would look like a triangle. Wave1.3 Wave2.2 wave3.1, with wave 3.1 having the most fresh top and wave 1.3 having the most fresh lower section.
You still might be right about it being impractical. Is the alternative to try the equivalent of “update glib, llvm, python and Numpy all at the same time and try to get them all working then stamp that as a release once tests pass”?
I know that we can make the tree, but we need to categorize the tree into strict levels, something that would be really hard to define. And it would get stale.
Wave1.0
glib0.1
llvm0.1
python0.1
numpy 0.1
Wave1.1
glib1.0 ← update to latest
llvm0.1 (test and fix)
python0.1 (test and fix, ex: maybe bump to python 0.2)
numpy 0.1 (test and fix)
Wave1.2
glibc1.0 (dont touch dont test)
llvm1.0. ← update to latest
python0.1 (test and fix)
numpy 0.1 (test and fix)
Wave1.3
glibc1.0 (dont touch dont test)
llvm1.0 (dont touch dont test)
python1.0 ← update to latest
numpy 0.1 (test and fix if needed)
Ok, new top level needed, let’s fork off of wave 1.1. But then we have a regression in llvm and python, ok, lets fork off of 1.3. Wait, python1.0 doesn’t work with glibc2.0, so we need to wait for it to get to that wave. For someone who wants a recent version of numpy, they need to go to an old, completed wave that made it all the way to the end where numpy was finally touched, and they need to wait until the next wave completely finishes. Also, what problem does this solve? If you want to get newer software from a newer wave near the end of the tree, you need to wait longer than if that package had just been updated by itself. If I want a new top level with and old bottom level, this works, but if I want a newer bottom with an older top, I need to wait until the newer bottom level’s wave completely finishes.
The alternative you propose is what is currently in place in Nixpkgs, which works. I like the current system, but I think for rapid iteration we should move to a segmented flakes like was suggested above.
1 Like
My one reservation with this is I think its important to have sub-packages (rust crate, npm module, etc), be independently installable. E.g. if auxpkg.rust2018.tokio is the wrong version, I should be able to easily install a different version from flakehub. If each needs an overlay system, then we should try to make it consistent across sub-package managers. For nix profile install, its a little weird since, like if two pythons are installed, and then we install the numpy flakehub flake, we would need a way to specify which python to install the numpy to. Or in other words the CLI profile install currently just can’t handle that case with a distributed system
1 Like
This raises another important concern: subpackages. Put another way, nested package sets. Flakes do not currently support these aside from the legacyPackages output.
1 Like
I think the best way to go about it is to rely on nix2 tooling for now, and then once we get the core team settled in work on nix3 flakes to enable recursive package sets. I think it’s not ideal, but the start of anything is always going to be rocky.
A little off-topic, but I think that this is a good starting point for Aux to differentiate itself – we could stabilize a lot of nix3 quickly and use it to tie auxpkgs together. Once we get the core team settled in, we could put this on the tracker for high priority, maybe.
3 Likes
Something that could potentially be interesting to keep both nix2 compatibility and flake orientation would be to use GitHub - edolstra/flake-compat as a way to bootstrap. This would be a minimal support vector that ensures both nix2 and nix3 can consume the “flakes”. I’ve used it in GitHub - bbjubjub2494/hostapd-mana.docker for example. Downside is we still need nix3 to lock dependencies.
2 Likes
Another option could be something like josh to keep a monorepo but make contributing to it easier. This would probably require some restructuring though.
2 Likes
I like the idea of using Aux to achieve technical advancements but I would not like to end up building upon sand pilars due to rushing over the implementation.
1 Like
josh sounds excellent if we go with a monorepo setup! I think this is what TVL uses for their monorepo too if anyone wants to see it in action:
- all git clone instructions in depot: context:global repo:^dep… - Sourcegraph
- the josh module: josh.nix - depot - Sourcegraph
1 Like
I’m still in support of moving away from a monorepo. I haven’t used josh before so I don’t have much of an opinion on it. Either way restructuring would be a huge task. I feel like in the restructuring process we have two main methods of going about it:
- Fork nixpkgs and break it up into its new structure
- Create a new repo that depends on nixpkgs as a flake input and work towards migrating everything into the new repo (or set of repos) to the point that we can drop the nixpkgs dependence
Edit: I feel the latter option may be more manageable as it allows us to slowly ramp up to maintaining our set of packages instead of maintaining 80000+ right at the start
3 Likes